Context

In January 2021 the Dutch government announced curfew/avondklok that forced
almost everyone to stay at home from 21:00 to 4:30.
Hypothesis
As a curfew is an unusual and a new thing, it will be useful to have
an app that will notify people before it starts.
Usefulness can be measured by gathering feedback from the app users.
As there are/were no plans to advertise or even promote the app at that stage,
the number of installations can’t be used as the success metric.
UX
A wristwatch from The Walking Dead: Saints & Sinners (VR zombie game) seemed like
the ideal interface for an app like that:

Aiming to achieve a similar experience, but without the zombies, the mockup looked like this:
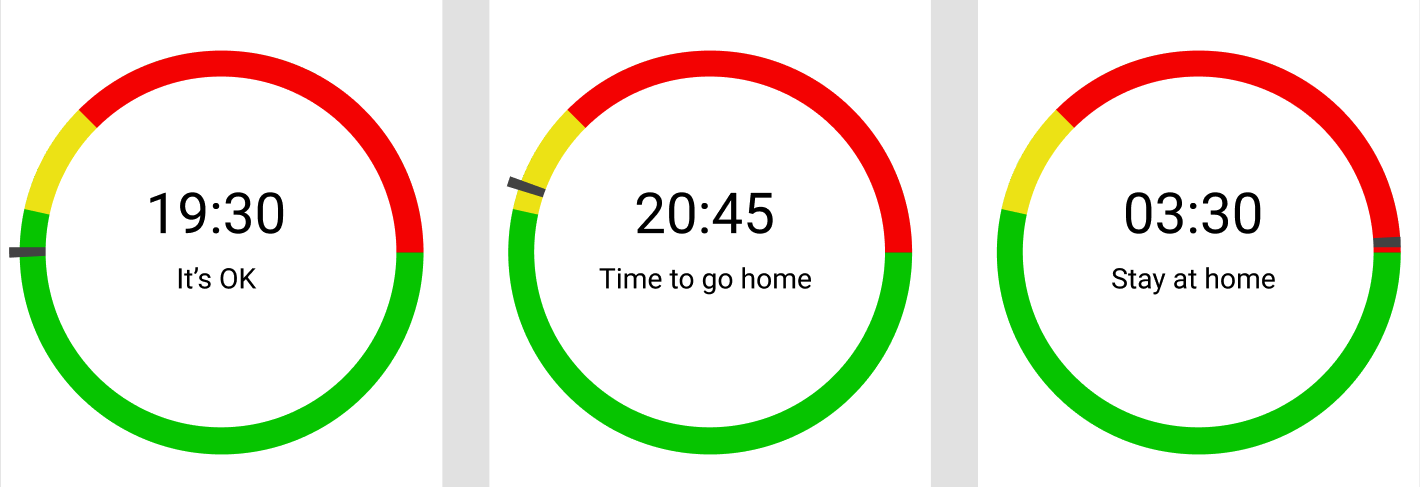
In the game, a player also hears a bell when the dangerous time starts.
The app uses push notifications instead.
Tech stack
As a possible tech stack React Native (with and without Expo), Flutter, and native (Kotlin and Swift)
were evaluated.
|
React Native |
React Native + Expo |
Flutter |
Kotlin + Swift |
| Familarity |
😊 |
😊 |
😐 |
😟 |
| Maturity |
😐 |
😐 |
😟 |
😊 |
| Tooling |
😟 |
😊 |
😐 |
😟 |
React Native with Expo was selected because:
- I’m more familiar with React Native than with the other options (haven’t touched native iOS at all).
- React Native finally looks mature enough.
- React + TypeScript is fairly nice to work with.
- Expo handles all the notifications related certificates.
- Expo handles all the release build signing.
- Expo provides OTA updates.
Release and delivery
Expo provides two kinds of releases:
- Full release that needs to be uploaded to stores.
- OTA release that automatically got fetched on app launch.
The full release process is done with Github Actions and Expo build infrastructure,
but still requires a maintainer to download the produced artifacts and upload them
manually to TestFlight and Google Play console:
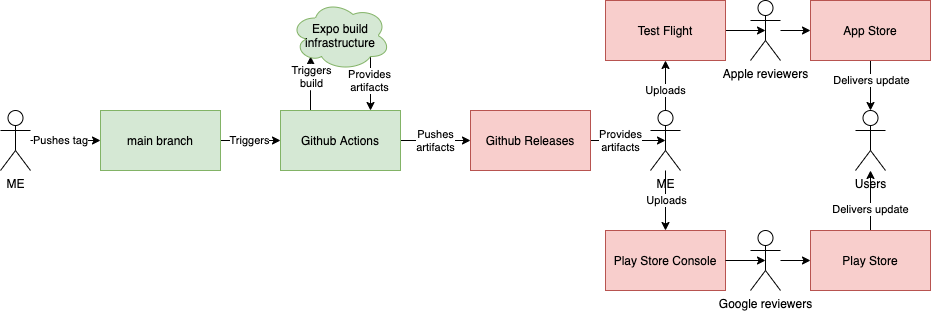 (green - safe and automated, red - manual)
(green - safe and automated, red - manual)
The OTA release happens on every push to main / every PR merge after tests and linters,
the delivery process is handled by Expo:
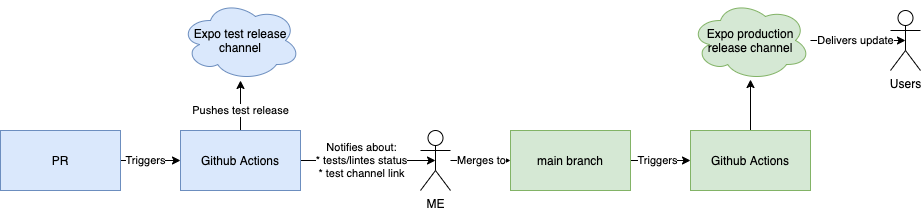 (green - safe and automated, blue - unsafe and automated)
(green - safe and automated, blue - unsafe and automated)
Processes
Despite the project having only me working on it, I decided to stick with kanban
at least to track the progress and don’t forget about the next steps.
As the board, Github Projects were used.
What went well
The UI didn’t get much bad feedback, and was easy to implement:
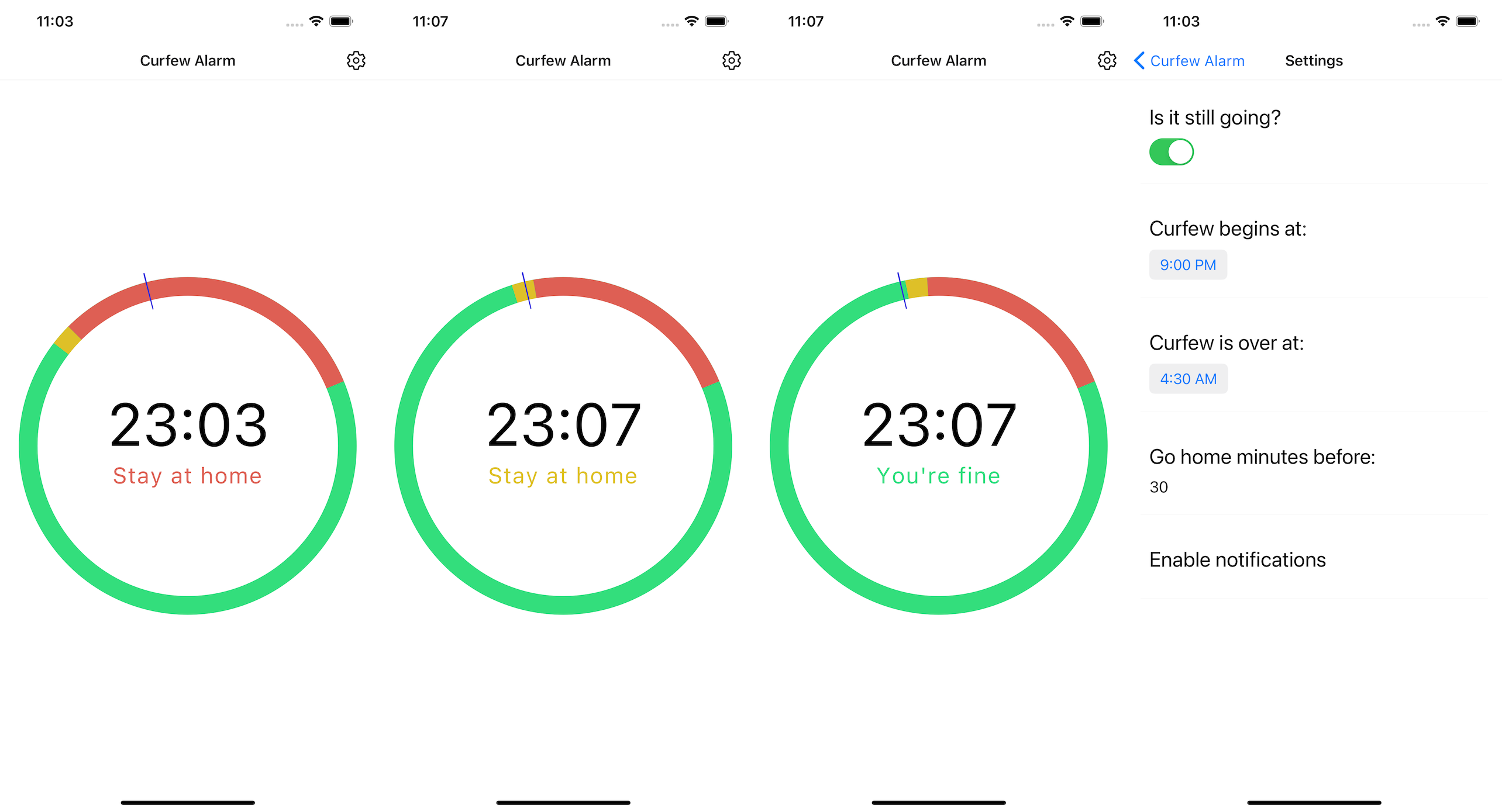
React Native + Expo + TypeScript stack was nice to work with,
there were no tooling related problems and even the type definitions were available
for all the dependencies.
The AppStore release process is surprisingly easy and fast.
The first release review took less than a day.
The OTA release process works and doesn’t require manual interactions.
Github Projects are fine to work with as the board.
The app actually works.
What could have been better
The selected tech stack probably is not the best for an app that needs to have reliable notifications.
Discovered downsides:
- Background tasks aren’t that reliable (seems like only a native solution can provide reliable background tasks).
- The app size is huge (50+ mb).
- Vendor lock on a third party, ejecting when you use a lot
@expo/ packages might not be that easy.
When the app receives an OTA update, the launch time is noticeable (around 3 seconds).
Google Play console review time is significantly longer than in the App Store.
The first review took more than a week.
The app isn’t actually that useful.
Links
 Recently I started to
look more and more at different directions to grow,
and Staff Engineer by Will Larson
looked like a relevant book for that. The book explains
the responsibilities of senior+ engineers in different companies
with examples and real-life stories, which are even interesting to read.
Recently I started to
look more and more at different directions to grow,
and Staff Engineer by Will Larson
looked like a relevant book for that. The book explains
the responsibilities of senior+ engineers in different companies
with examples and real-life stories, which are even interesting to read. I heard a bunch of good
things about
I heard a bunch of good
things about  Recently I finished reading
Recently I finished reading
 A few weeks ago
I finished reading
A few weeks ago
I finished reading  Recently I’ve read
Recently I’ve read  Not so long ago I decided to
read
Not so long ago I decided to
read  Recently
I wanted to read something about the old school and not
new fancy tech management, so I decided to read
Recently
I wanted to read something about the old school and not
new fancy tech management, so I decided to read
 Not so long ago I stumbled upon
Not so long ago I stumbled upon
 Recently I thought that
it might be nice to read
Recently I thought that
it might be nice to read