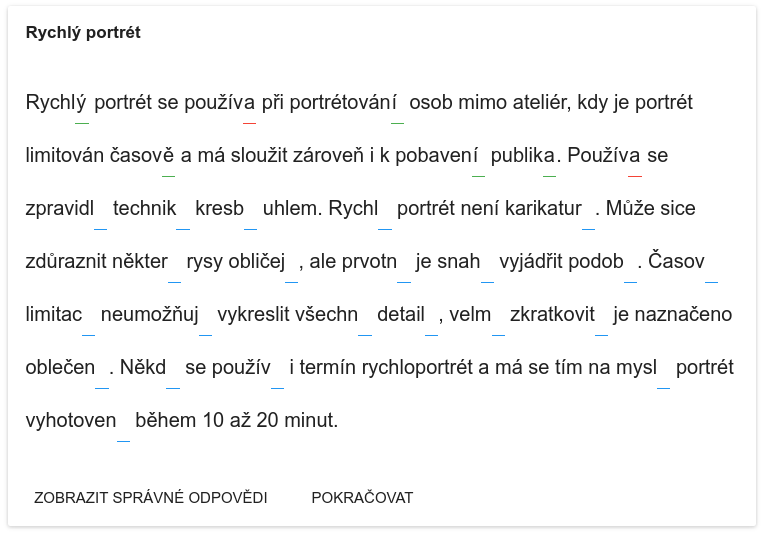
In the previous September I started learning Czech language, it’s interesting and not so hard, but a few things are really pain in the ass. One of them – word’s endings. They varies between declinations, kinds and forms. And there’s a lot of exceptions. So I decided to write a little app, that would grab random texts from internet, replace word’s endings with inputs and check correctness of values in inputs. And also I wanted make app as small as possible, ideally even server-less.
As a data source I chose Czech Wikipedia, it’s API has all I need:
-
get random article title – ?action=query&list=random;
-
get article summary by title without markup – ?action=query&prop=extracts;
-
JSONP, so app can be server-less – cross-site requests.
We can easily try this API with curl:
# Get random article title:
➜ curl "https://cs.wikipedia.org/w/api.php?action=query&list=random&rnlimit=1&rnnamespace=0&format=json"
{"batchcomplete":"","continue":{"rncontinue":"0.126319054816|0.12632136624|1223411|0","continue":"-||"},"query":{"random":[{"id":1248403,"ns":0,"title":"Weinmannia"}]}}%
# Get article summary by title:
➜ curl "https://cs.wikipedia.org/w/api.php?action=query&prop=extracts&exintro=&explaintext=&titles=Weinmannia&format=json"
{"batchcomplete":"","query":{"pages":{"1248403":{"pageid":1248403,"ns":0,"title":"Weinmannia","extract":"Weinmannia je rod rostlin z \u010deledi kunoniovit\u00e9 (Cunoniaceae). Jsou to d\u0159eviny se zpe\u0159en\u00fdmi nebo jednoduch\u00fdmi vst\u0159\u00edcn\u00fdmi listy a drobn\u00fdmi kv\u011bty v klasovit\u00fdch nebo hroznovit\u00fdch kv\u011btenstv\u00edch. Rod zahrnuje asi 150 druh\u016f. Je roz\u0161\u00ed\u0159en zejm\u00e9na na ji\u017en\u00ed polokouli v m\u00edrn\u00e9m p\u00e1su a v tropick\u00fdch hor\u00e1ch. Vyskytuje se v Latinsk\u00e9 Americe, jihov\u00fdchodn\u00ed Asii, Tichomo\u0159\u00ed, Madagaskaru a Nov\u00e9m Z\u00e9landu.\nRostliny byly v minulosti t\u011b\u017eeny zejm\u00e9na jako zdroj t\u0159\u00edslovin a d\u0159eva k v\u00fdrob\u011b d\u0159ev\u011bn\u00e9ho uhl\u00ed. Maj\u00ed tak\u00e9 v\u00fdznam v domorod\u00e9 medic\u00edn\u011b."}}}}%
For frontend I used React with Redux and Material-UI. I didn’t wanted to mess with webpack/etc configs, so I just used Create React App. And it works pretty well.
Mostly implementation isn’t interesting, it’s just a standard react+redux app. But there was a few not so obvious problems.
The first was finding word’s endings, there’s no tools for nlp for Czech in JavaScript world. But the language has limited set of word’s endings, so hardcoding them and checking every long enough word works:
const ENDS = [
'etem',
'ého',
...
'ě',
];
(word) => {
if (word.length < 4) {
return null;
}
for (const end of ENDS) {
if (word.endsWith(end) && (word.length - end.length) > 3) {
return end;
}
}
return null;
}
Another problem was extracting words from text, regular expressions like (\w+) doesn’t work
with words like křižovatka. And also I need to extract not only words, but a
symbols before and after the word. So I used ugly regexp:
(part) => {
const matched = part.match(/([.,\/#!$%\^&\*;:{}=\-_`~()]*)([^.,\/#!$%\^&\*;:{}=\-_`~()]*)([.,\/#!$%\^&\*;:{}=\-_`~()]*)/);
return matched.slice(1);
}
The last non-obvious part was to make client side routing work properly on heroku (on page refresh, etc).
But it was solved by just adding static.json with content like:
{
"root": "build/",
"clean_urls": false,
"routes": {
"/**": "index.html"
},
"https_only": true
}
And that’s all. Result app is a bit hackish and a bit ugly, but it’s useful, at least for me.