As everyone knows a lot of subreddits are opinionated, so I thought that it might be interesting to measure the opinion of different subreddits. Not trying to start a holy war I’ve specifically decided to ignore r/worldnews and similar subreddits, and chose a semi-random topic – “Apu reportedly being written out of The Simpsons”.
For accessing Reddit API I’ve decided to use praw, because it already implements all OAuth related stuff and almost the same as REST API.
As a first step I’ve found all posts with that URL and populated pandas DataFrame:
[*posts] = reddit.subreddit('all').search(f"url:{url}", limit=1000)
posts_df = pd.DataFrame(
[(post.id, post.subreddit.display_name, post.title, post.score,
datetime.utcfromtimestamp(post.created_utc), post.url,
post.num_comments, post.upvote_ratio)
for post in posts],
columns=['id', 'subreddit', 'title', 'score', 'created',
'url', 'num_comments', 'upvote_ratio'])
posts_df.head()
id subreddit title score created url num_comments upvote_ratio
0 9rmz0o television Apu to be written out of The Simpsons 1455 2018-10-26 17:49:00 https://www.indiewire.com/2018/10/simpsons-drop-apu-character-adi-shankar-12... 1802 0.88
1 9rnu73 GamerGhazi Apu reportedly being written out of The Simpsons 73 2018-10-26 19:30:39 https://www.indiewire.com/2018/10/simpsons-drop-apu-character-adi-shankar-12... 95 0.83
2 9roen1 worstepisodeever The Simpsons Writing Out Apu 14 2018-10-26 20:38:21 https://www.indiewire.com/2018/10/simpsons-drop-apu-character-adi-shankar-12... 22 0.94
3 9rq7ov ABCDesis ‘The Simpsons’ Is Eliminating Apu, But Producer Adi Shankar Found the Perfec... 26 2018-10-27 00:40:28 https://www.indiewire.com/2018/10/simpsons-drop-apu-character-adi-shankar-12... 11 0.84
4 9rnd6y doughboys Apu to be written out of The Simpsons 24 2018-10-26 18:34:58 https://www.indiewire.com/2018/10/simpsons-drop-apu-character-adi-shankar-12... 9 0.87
The easiest metric for opinion is upvote ratio:
posts_df[['subreddit', 'upvote_ratio']] \
.groupby('subreddit') \
.mean()['upvote_ratio'] \
.reset_index() \
.plot(kind='barh', x='subreddit', y='upvote_ratio',
title='Upvote ratio', legend=False) \
.xaxis \
.set_major_formatter(FuncFormatter(lambda x, _: '{:.1f}%'.format(x * 100)))
But it doesn’t say us anything:
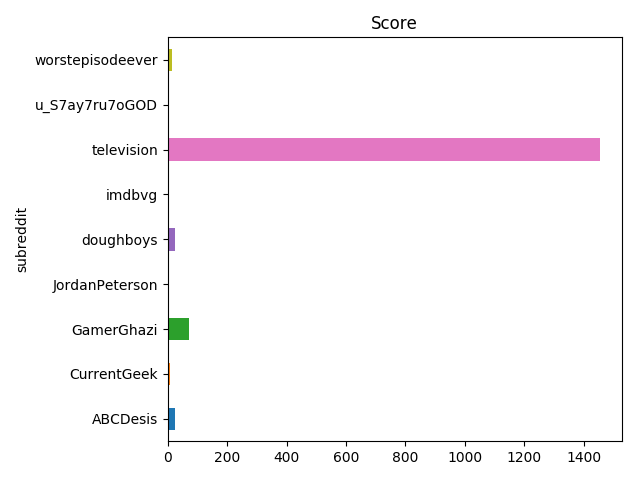
The most straightforward metric to measure is score:
posts_df[['subreddit', 'score']] \
.groupby('subreddit') \
.sum()['score'] \
.reset_index() \
.plot(kind='barh', x='subreddit', y='score', title='Score', legend=False)
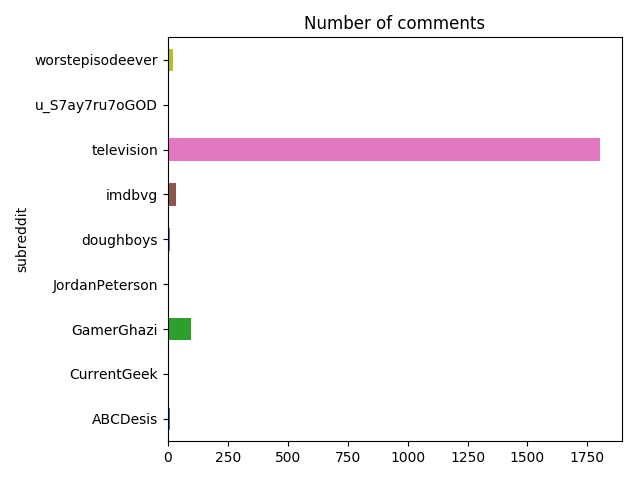
A second obvious metric is a number of comments:
posts_df[['subreddit', 'num_comments']] \
.groupby('subreddit') \
.sum()['num_comments'] \
.reset_index() \
.plot(kind='barh', x='subreddit', y='num_comments',
title='Number of comments', legend=False)
As absolute numbers can’t say us anything about an opinion of a subbreddit, I’ve decided to calculate normalized score and number of comments with data from the last 1000 of posts from the subreddit:
def normalize(post):
[*subreddit_posts] = reddit.subreddit(post.subreddit.display_name).new(limit=1000)
subreddit_posts_df = pd.DataFrame([(post.id, post.score, post.num_comments)
for post in subreddit_posts],
columns=('id', 'score', 'num_comments'))
norm_score = ((post.score - subreddit_posts_df.score.mean())
/ (subreddit_posts_df.score.max() - subreddit_posts_df.score.min()))
norm_num_comments = ((post.num_comments - subreddit_posts_df.num_comments.mean())
/ (subreddit_posts_df.num_comments.max() - subreddit_posts_df.num_comments.min()))
return norm_score, norm_num_comments
normalized_vals = pd \
.DataFrame([normalize(post) for post in posts],
columns=['norm_score', 'norm_num_comments']) \
.fillna(0)
posts_df[['norm_score', 'norm_num_comments']] = normalized_vals
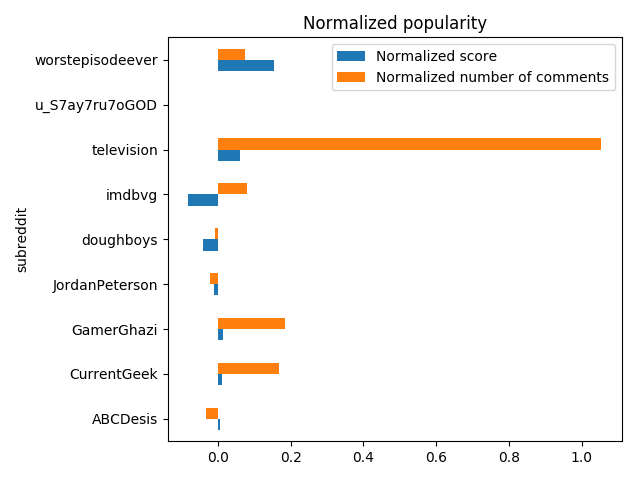
And look at the popularity of the link based on the numbers:
posts_df[['subreddit', 'norm_score', 'norm_num_comments']] \
.groupby('subreddit') \
.sum()[['norm_score', 'norm_num_comments']] \
.reset_index() \
.rename(columns={'norm_score': 'Normalized score',
'norm_num_comments': 'Normalized number of comments'}) \
.plot(kind='barh', x='subreddit',title='Normalized popularity')
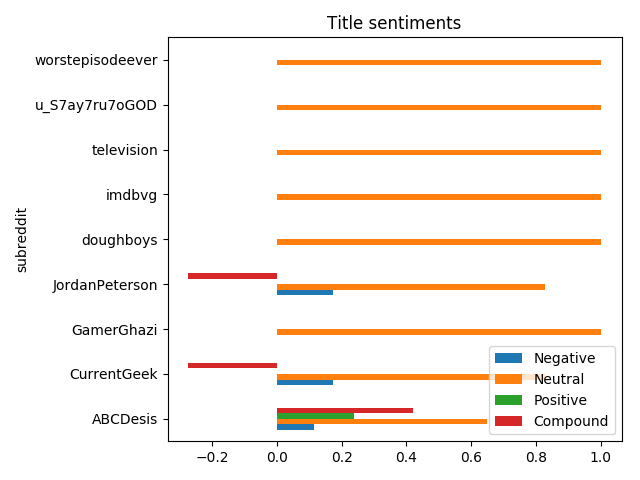
As in different subreddits a link can be shared with a different title with totally different sentiments, it seemed interesting to do sentiment analysis on titles:
sid = SentimentIntensityAnalyzer()
posts_sentiments = posts_df.title.apply(sid.polarity_scores).apply(pd.Series)
posts_df = posts_df.assign(title_neg=posts_sentiments.neg,
title_neu=posts_sentiments.neu,
title_pos=posts_sentiments.pos,
title_compound=posts_sentiments['compound'])
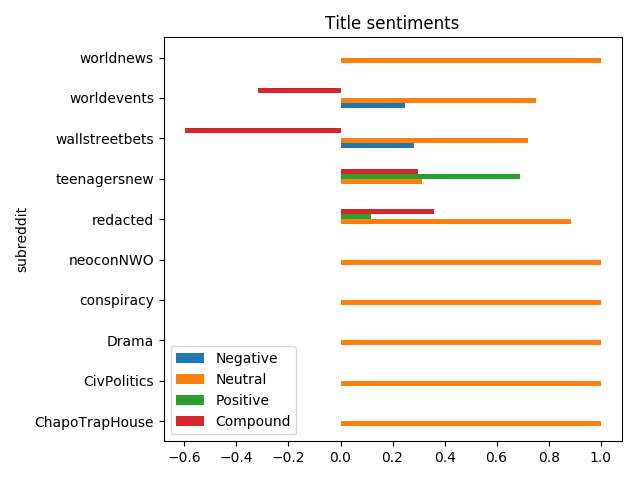
And notice that people are using the same title almost every time:
posts_df[['subreddit', 'title_neg', 'title_neu', 'title_pos', 'title_compound']] \
.groupby('subreddit') \
.sum()[['title_neg', 'title_neu', 'title_pos', 'title_compound']] \
.reset_index() \
.rename(columns={'title_neg': 'Title negativity',
'title_pos': 'Title positivity',
'title_neu': 'Title neutrality',
'title_compound': 'Title sentiment'}) \
.plot(kind='barh', x='subreddit', title='Title sentiments', legend=True)
Sentiments of a title isn’t that interesting, but it might be much
more interesting for comments. I’ve decided to only handle root
comments as replies to comments might be totally not related to
post subject, and they’re making everything more complicated.
For comments analysis I’ve bucketed them to five buckets by
compound value, and calculated mean normalized score and percentage:
posts_comments_df = pd \
.concat([handle_post_comments(post) for post in posts]) \ # handle_post_comments is huge and available in the gist
.fillna(0)
>>> posts_comments_df.head()
key root_comments_key root_comments_neg_neg_amount root_comments_neg_neg_norm_score root_comments_neg_neg_percent root_comments_neg_neu_amount root_comments_neg_neu_norm_score root_comments_neg_neu_percent root_comments_neu_neu_amount root_comments_neu_neu_norm_score root_comments_neu_neu_percent root_comments_pos_neu_amount root_comments_pos_neu_norm_score root_comments_pos_neu_percent root_comments_pos_pos_amount root_comments_pos_pos_norm_score root_comments_pos_pos_percent root_comments_post_id
0 9rmz0o 0 87.0 -0.005139 0.175758 98.0 0.019201 0.197980 141.0 -0.007125 0.284848 90.0 -0.010092 0.181818 79 0.006054 0.159596 9rmz0o
0 9rnu73 0 12.0 0.048172 0.134831 15.0 -0.061331 0.168539 35.0 -0.010538 0.393258 13.0 -0.015762 0.146067 14 0.065402 0.157303 9rnu73
0 9roen1 0 9.0 -0.094921 0.450000 1.0 0.025714 0.050000 5.0 0.048571 0.250000 0.0 0.000000 0.000000 5 0.117143 0.250000 9roen1
0 9rq7ov 0 1.0 0.476471 0.100000 2.0 -0.523529 0.200000 0.0 0.000000 0.000000 1.0 -0.229412 0.100000 6 0.133333 0.600000 9rq7ov
0 9rnd6y 0 0.0 0.000000 0.000000 0.0 0.000000 0.000000 0.0 0.000000 0.000000 5.0 -0.027778 0.555556 4 0.034722 0.444444 9rnd6y
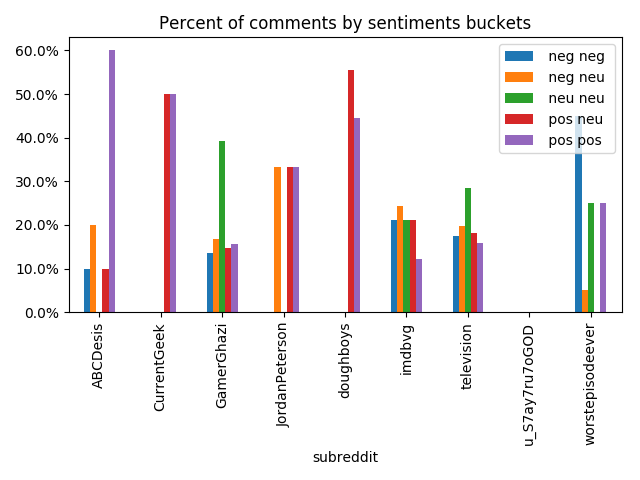
So now we can get a percent of comments by sentiments buckets:
percent_columns = ['root_comments_neg_neg_percent',
'root_comments_neg_neu_percent', 'root_comments_neu_neu_percent',
'root_comments_pos_neu_percent', 'root_comments_pos_pos_percent']
posts_with_comments_df[['subreddit'] + percent_columns] \
.groupby('subreddit') \
.mean()[percent_columns] \
.reset_index() \
.rename(columns={column: column[13:-7].replace('_', ' ')
for column in percent_columns}) \
.plot(kind='bar', x='subreddit', legend=True,
title='Percent of comments by sentiments buckets') \
.yaxis \
.set_major_formatter(FuncFormatter(lambda y, _: '{:.1f}%'.format(y * 100)))
It’s easy to spot that on less popular subreddits comments are more opinionated:
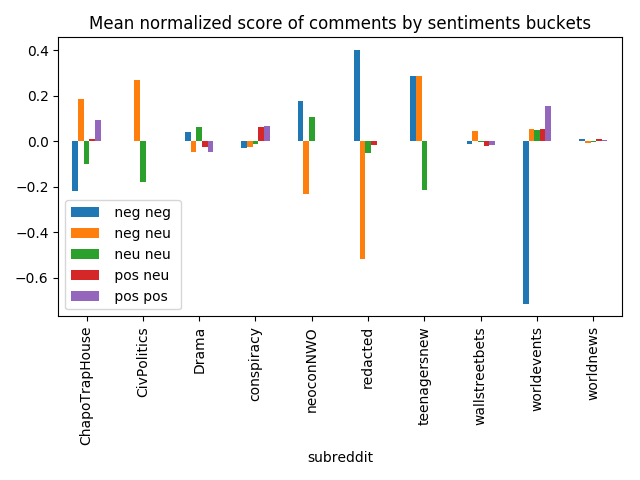
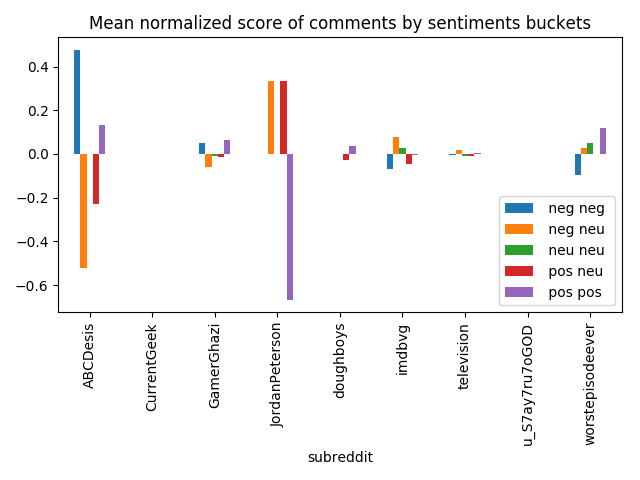
The same can be spotted with mean normalized scores:
norm_score_columns = ['root_comments_neg_neg_norm_score',
'root_comments_neg_neu_norm_score',
'root_comments_neu_neu_norm_score',
'root_comments_pos_neu_norm_score',
'root_comments_pos_pos_norm_score']
posts_with_comments_df[['subreddit'] + norm_score_columns] \
.groupby('subreddit') \
.mean()[norm_score_columns] \
.reset_index() \
.rename(columns={column: column[13:-10].replace('_', ' ')
for column in norm_score_columns}) \
.plot(kind='bar', x='subreddit', legend=True,
title='Mean normalized score of comments by sentiments buckets')
Although those plots are fun even with that link, it’s more fun with something more controversial. I’ve picked one of the recent posts from r/worldnews, and it’s easy to notice that different subreddits present the news in a different way:
And comments are rated differently, some subreddits are more neutral, some definitely not: