| 10 |
1817.04 |
1 days 19:50:00 |
AMS |
SVO |
2019-07-11 |
203.07 |
2019-07-11 21:15:00+02:00 |
2019-07-12 01:30:00+03:00 |
1 |
03:15:00 |
Amsterdam |
Moscow |
Amsterdam ✈️ Moscow |
DME |
IKT |
2019-07-15 |
198.03 |
2019-07-15 18:35:00+03:00 |
2019-07-16 05:05:00+08:00 |
1 |
05:30:00 |
Moscow |
Irkutsk |
Moscow ✈️ Irkutsk |
IKT |
PEK |
2019-07-22 |
154.11 |
2019-07-22 01:50:00+08:00 |
2019-07-22 04:40:00+08:00 |
1 |
02:50:00 |
Irkutsk |
Beijing |
Irkutsk ✈️ Beijing |
PEK |
SHA |
2019-07-25 |
171.64 |
2019-07-25 21:50:00+08:00 |
2019-07-25 23:55:00+08:00 |
1 |
02:05:00 |
Beijing |
Shanghai |
Beijing ✈️ Shanghai |
PVG |
NRT |
2019-07-28 |
394.07 |
2019-07-28 17:15:00+08:00 |
2019-07-28 20:40:00+09:00 |
1 |
02:25:00 |
Shanghai |
Tokyo |
Shanghai ✈️ Tokyo |
NRT |
AMS |
2019-07-31 |
696.12 |
2019-07-31 17:55:00+09:00 |
2019-08-01 14:40:00+02:00 |
2 |
1 days 03:45:00 |
Tokyo |
Amsterdam |
Tokyo ✈️ Amsterdam |
| 40 |
1817.04 |
1 days 19:50:00 |
AMS |
SVO |
2019-07-11 |
203.07 |
2019-07-11 21:15:00+02:00 |
2019-07-12 01:30:00+03:00 |
1 |
03:15:00 |
Amsterdam |
Moscow |
Amsterdam ✈️ Moscow |
DME |
IKT |
2019-07-15 |
198.03 |
2019-07-15 18:35:00+03:00 |
2019-07-16 05:05:00+08:00 |
1 |
05:30:00 |
Moscow |
Irkutsk |
Moscow ✈️ Irkutsk |
IKT |
PEK |
2019-07-22 |
154.11 |
2019-07-22 01:50:00+08:00 |
2019-07-22 04:40:00+08:00 |
1 |
02:50:00 |
Irkutsk |
Beijing |
Irkutsk ✈️ Beijing |
PEK |
SHA |
2019-07-25 |
171.64 |
2019-07-25 21:50:00+08:00 |
2019-07-25 23:55:00+08:00 |
1 |
02:05:00 |
Beijing |
Shanghai |
Beijing ✈️ Shanghai |
SHA |
NRT |
2019-07-28 |
394.07 |
2019-07-28 17:15:00+08:00 |
2019-07-28 20:40:00+09:00 |
1 |
02:25:00 |
Shanghai |
Tokyo |
Shanghai ✈️ Tokyo |
NRT |
AMS |
2019-07-31 |
696.12 |
2019-07-31 17:55:00+09:00 |
2019-08-01 14:40:00+02:00 |
2 |
1 days 03:45:00 |
Tokyo |
Amsterdam |
Tokyo ✈️ Amsterdam |
| 0 |
1817.04 |
1 days 20:00:00 |
AMS |
SVO |
2019-07-10 |
203.07 |
2019-07-10 21:15:00+02:00 |
2019-07-11 01:30:00+03:00 |
1 |
03:15:00 |
Amsterdam |
Moscow |
Amsterdam ✈️ Moscow |
DME |
IKT |
2019-07-15 |
198.03 |
2019-07-15 18:35:00+03:00 |
2019-07-16 05:05:00+08:00 |
1 |
05:30:00 |
Moscow |
Irkutsk |
Moscow ✈️ Irkutsk |
IKT |
PEK |
2019-07-22 |
154.11 |
2019-07-22 01:50:00+08:00 |
2019-07-22 04:40:00+08:00 |
1 |
02:50:00 |
Irkutsk |
Beijing |
Irkutsk ✈️ Beijing |
PEK |
SHA |
2019-07-25 |
171.64 |
2019-07-25 13:00:00+08:00 |
2019-07-25 15:15:00+08:00 |
1 |
02:15:00 |
Beijing |
Shanghai |
Beijing ✈️ Shanghai |
PVG |
NRT |
2019-07-28 |
394.07 |
2019-07-28 17:15:00+08:00 |
2019-07-28 20:40:00+09:00 |
1 |
02:25:00 |
Shanghai |
Tokyo |
Shanghai ✈️ Tokyo |
NRT |
AMS |
2019-07-31 |
696.12 |
2019-07-31 17:55:00+09:00 |
2019-08-01 14:40:00+02:00 |
2 |
1 days 03:45:00 |
Tokyo |
Amsterdam |
Tokyo ✈️ Amsterdam |
| 70 |
1817.04 |
1 days 20:00:00 |
AMS |
SVO |
2019-07-10 |
203.07 |
2019-07-10 11:50:00+02:00 |
2019-07-10 16:05:00+03:00 |
1 |
03:15:00 |
Amsterdam |
Moscow |
Amsterdam ✈️ Moscow |
DME |
IKT |
2019-07-15 |
198.03 |
2019-07-15 18:35:00+03:00 |
2019-07-16 05:05:00+08:00 |
1 |
05:30:00 |
Moscow |
Irkutsk |
Moscow ✈️ Irkutsk |
IKT |
PEK |
2019-07-22 |
154.11 |
2019-07-22 01:50:00+08:00 |
2019-07-22 04:40:00+08:00 |
1 |
02:50:00 |
Irkutsk |
Beijing |
Irkutsk ✈️ Beijing |
PEK |
SHA |
2019-07-25 |
171.64 |
2019-07-25 18:00:00+08:00 |
2019-07-25 20:15:00+08:00 |
1 |
02:15:00 |
Beijing |
Shanghai |
Beijing ✈️ Shanghai |
PVG |
NRT |
2019-07-28 |
394.07 |
2019-07-28 17:15:00+08:00 |
2019-07-28 20:40:00+09:00 |
1 |
02:25:00 |
Shanghai |
Tokyo |
Shanghai ✈️ Tokyo |
NRT |
AMS |
2019-07-31 |
696.12 |
2019-07-31 17:55:00+09:00 |
2019-08-01 14:40:00+02:00 |
2 |
1 days 03:45:00 |
Tokyo |
Amsterdam |
Tokyo ✈️ Amsterdam |
| 60 |
1817.04 |
1 days 20:00:00 |
AMS |
SVO |
2019-07-10 |
203.07 |
2019-07-10 11:50:00+02:00 |
2019-07-10 16:05:00+03:00 |
1 |
03:15:00 |
Amsterdam |
Moscow |
Amsterdam ✈️ Moscow |
DME |
IKT |
2019-07-15 |
198.03 |
2019-07-15 18:35:00+03:00 |
2019-07-16 05:05:00+08:00 |
1 |
05:30:00 |
Moscow |
Irkutsk |
Moscow ✈️ Irkutsk |
IKT |
PEK |
2019-07-22 |
154.11 |
2019-07-22 01:50:00+08:00 |
2019-07-22 04:40:00+08:00 |
1 |
02:50:00 |
Irkutsk |
Beijing |
Irkutsk ✈️ Beijing |
PEK |
SHA |
2019-07-25 |
171.64 |
2019-07-25 13:00:00+08:00 |
2019-07-25 15:15:00+08:00 |
1 |
02:15:00 |
Beijing |
Shanghai |
Beijing ✈️ Shanghai |
PVG |
NRT |
2019-07-28 |
394.07 |
2019-07-28 17:15:00+08:00 |
2019-07-28 20:40:00+09:00 |
1 |
02:25:00 |
Shanghai |
Tokyo |
Shanghai ✈️ Tokyo |
NRT |
AMS |
2019-07-31 |
696.12 |
2019-07-31 17:55:00+09:00 |
2019-08-01 14:40:00+02:00 |
2 |
1 days 03:45:00 |
Tokyo |
Amsterdam |
Tokyo ✈️ Amsterdam |
| 0 |
1817.04 |
1 days 20:00:00 |
AMS |
SVO |
2019-07-11 |
203.07 |
2019-07-11 21:15:00+02:00 |
2019-07-12 01:30:00+03:00 |
1 |
03:15:00 |
Amsterdam |
Moscow |
Amsterdam ✈️ Moscow |
DME |
IKT |
2019-07-15 |
198.03 |
2019-07-15 18:35:00+03:00 |
2019-07-16 05:05:00+08:00 |
1 |
05:30:00 |
Moscow |
Irkutsk |
Moscow ✈️ Irkutsk |
IKT |
PEK |
2019-07-22 |
154.11 |
2019-07-22 01:50:00+08:00 |
2019-07-22 04:40:00+08:00 |
1 |
02:50:00 |
Irkutsk |
Beijing |
Irkutsk ✈️ Beijing |
PEK |
SHA |
2019-07-25 |
171.64 |
2019-07-25 13:00:00+08:00 |
2019-07-25 15:15:00+08:00 |
1 |
02:15:00 |
Beijing |
Shanghai |
Beijing ✈️ Shanghai |
PVG |
NRT |
2019-07-28 |
394.07 |
2019-07-28 17:15:00+08:00 |
2019-07-28 20:40:00+09:00 |
1 |
02:25:00 |
Shanghai |
Tokyo |
Shanghai ✈️ Tokyo |
NRT |
AMS |
2019-07-31 |
696.12 |
2019-07-31 17:55:00+09:00 |
2019-08-01 14:40:00+02:00 |
2 |
1 days 03:45:00 |
Tokyo |
Amsterdam |
Tokyo ✈️ Amsterdam |
| 10 |
1817.04 |
1 days 20:05:00 |
AMS |
SVO |
2019-07-10 |
203.07 |
2019-07-10 11:50:00+02:00 |
2019-07-10 16:05:00+03:00 |
1 |
03:15:00 |
Amsterdam |
Moscow |
Amsterdam ✈️ Moscow |
DME |
IKT |
2019-07-15 |
198.03 |
2019-07-15 18:35:00+03:00 |
2019-07-16 05:05:00+08:00 |
1 |
05:30:00 |
Moscow |
Irkutsk |
Moscow ✈️ Irkutsk |
IKT |
PEK |
2019-07-22 |
154.11 |
2019-07-22 01:50:00+08:00 |
2019-07-22 04:40:00+08:00 |
1 |
02:50:00 |
Irkutsk |
Beijing |
Irkutsk ✈️ Beijing |
PEK |
SHA |
2019-07-25 |
171.64 |
2019-07-25 12:00:00+08:00 |
2019-07-25 14:20:00+08:00 |
1 |
02:20:00 |
Beijing |
Shanghai |
Beijing ✈️ Shanghai |
PVG |
NRT |
2019-07-28 |
394.07 |
2019-07-28 17:15:00+08:00 |
2019-07-28 20:40:00+09:00 |
1 |
02:25:00 |
Shanghai |
Tokyo |
Shanghai ✈️ Tokyo |
NRT |
AMS |
2019-07-31 |
696.12 |
2019-07-31 17:55:00+09:00 |
2019-08-01 14:40:00+02:00 |
2 |
1 days 03:45:00 |
Tokyo |
Amsterdam |
Tokyo ✈️ Amsterdam |
| 40 |
1817.04 |
1 days 20:05:00 |
AMS |
SVO |
2019-07-10 |
203.07 |
2019-07-10 11:50:00+02:00 |
2019-07-10 16:05:00+03:00 |
1 |
03:15:00 |
Amsterdam |
Moscow |
Amsterdam ✈️ Moscow |
DME |
IKT |
2019-07-15 |
198.03 |
2019-07-15 18:35:00+03:00 |
2019-07-16 05:05:00+08:00 |
1 |
05:30:00 |
Moscow |
Irkutsk |
Moscow ✈️ Irkutsk |
IKT |
PEK |
2019-07-22 |
154.11 |
2019-07-22 01:50:00+08:00 |
2019-07-22 04:40:00+08:00 |
1 |
02:50:00 |
Irkutsk |
Beijing |
Irkutsk ✈️ Beijing |
PEK |
SHA |
2019-07-25 |
171.64 |
2019-07-25 12:00:00+08:00 |
2019-07-25 14:20:00+08:00 |
1 |
02:20:00 |
Beijing |
Shanghai |
Beijing ✈️ Shanghai |
SHA |
NRT |
2019-07-28 |
394.07 |
2019-07-28 17:15:00+08:00 |
2019-07-28 20:40:00+09:00 |
1 |
02:25:00 |
Shanghai |
Tokyo |
Shanghai ✈️ Tokyo |
NRT |
AMS |
2019-07-31 |
696.12 |
2019-07-31 17:55:00+09:00 |
2019-08-01 14:40:00+02:00 |
2 |
1 days 03:45:00 |
Tokyo |
Amsterdam |
Tokyo ✈️ Amsterdam |
| 70 |
1817.04 |
1 days 20:05:00 |
AMS |
SVO |
2019-07-11 |
203.07 |
2019-07-11 21:15:00+02:00 |
2019-07-12 01:30:00+03:00 |
1 |
03:15:00 |
Amsterdam |
Moscow |
Amsterdam ✈️ Moscow |
DME |
IKT |
2019-07-15 |
198.03 |
2019-07-15 18:35:00+03:00 |
2019-07-16 05:05:00+08:00 |
1 |
05:30:00 |
Moscow |
Irkutsk |
Moscow ✈️ Irkutsk |
IKT |
PEK |
2019-07-22 |
154.11 |
2019-07-22 01:50:00+08:00 |
2019-07-22 04:40:00+08:00 |
1 |
02:50:00 |
Irkutsk |
Beijing |
Irkutsk ✈️ Beijing |
PEK |
SHA |
2019-07-25 |
171.64 |
2019-07-25 18:30:00+08:00 |
2019-07-25 20:50:00+08:00 |
1 |
02:20:00 |
Beijing |
Shanghai |
Beijing ✈️ Shanghai |
PVG |
NRT |
2019-07-28 |
394.07 |
2019-07-28 17:15:00+08:00 |
2019-07-28 20:40:00+09:00 |
1 |
02:25:00 |
Shanghai |
Tokyo |
Shanghai ✈️ Tokyo |
NRT |
AMS |
2019-07-31 |
696.12 |
2019-07-31 17:55:00+09:00 |
2019-08-01 14:40:00+02:00 |
2 |
1 days 03:45:00 |
Tokyo |
Amsterdam |
Tokyo ✈️ Amsterdam |
| 60 |
1817.04 |
1 days 20:05:00 |
AMS |
SVO |
2019-07-11 |
203.07 |
2019-07-11 21:15:00+02:00 |
2019-07-12 01:30:00+03:00 |
1 |
03:15:00 |
Amsterdam |
Moscow |
Amsterdam ✈️ Moscow |
DME |
IKT |
2019-07-15 |
198.03 |
2019-07-15 18:35:00+03:00 |
2019-07-16 05:05:00+08:00 |
1 |
05:30:00 |
Moscow |
Irkutsk |
Moscow ✈️ Irkutsk |
IKT |
PEK |
2019-07-22 |
154.11 |
2019-07-22 01:50:00+08:00 |
2019-07-22 04:40:00+08:00 |
1 |
02:50:00 |
Irkutsk |
Beijing |
Irkutsk ✈️ Beijing |
PEK |
SHA |
2019-07-25 |
171.64 |
2019-07-25 11:00:00+08:00 |
2019-07-25 13:20:00+08:00 |
1 |
02:20:00 |
Beijing |
Shanghai |
Beijing ✈️ Shanghai |
PVG |
NRT |
2019-07-28 |
394.07 |
2019-07-28 17:15:00+08:00 |
2019-07-28 20:40:00+09:00 |
1 |
02:25:00 |
Shanghai |
Tokyo |
Shanghai ✈️ Tokyo |
NRT |
AMS |
2019-07-31 |
696.12 |
2019-07-31 17:55:00+09:00 |
2019-08-01 14:40:00+02:00 |
2 |
1 days 03:45:00 |
Tokyo |
Amsterdam |
Tokyo ✈️ Amsterdam |
 Recently I decided
to up my “microservices” game a bit and read
Monolith To Microservices by Sam Newman.
I enjoyed this book more than the first microservices book, it’s not so upbeat and cheerful, and
doesn’t have this annoying “everything should be on microservices” vibe, it even sometimes
suggests that something might be better not as a microservice. Apart from that, the book covers
a bunch of patterns for gradual extraction of parts of a monolith to a few microservices
in an iteretive way. It also covers a few ways to separate the storage without breaking
existing applications.
Recently I decided
to up my “microservices” game a bit and read
Monolith To Microservices by Sam Newman.
I enjoyed this book more than the first microservices book, it’s not so upbeat and cheerful, and
doesn’t have this annoying “everything should be on microservices” vibe, it even sometimes
suggests that something might be better not as a microservice. Apart from that, the book covers
a bunch of patterns for gradual extraction of parts of a monolith to a few microservices
in an iteretive way. It also covers a few ways to separate the storage without breaking
existing applications. A few months ago I was
a bit hyped about
A few months ago I was
a bit hyped about  Recently I started to
go a bit deeper in data processing and decided that it would be nice
to read
Recently I started to
go a bit deeper in data processing and decided that it would be nice
to read
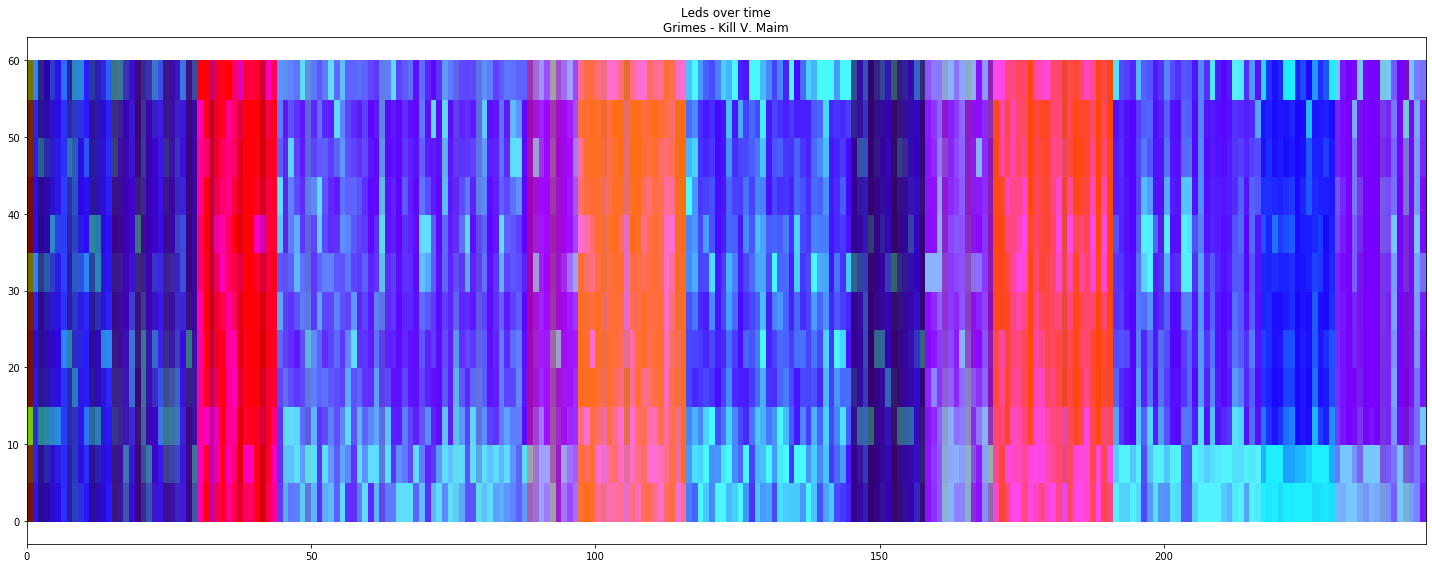
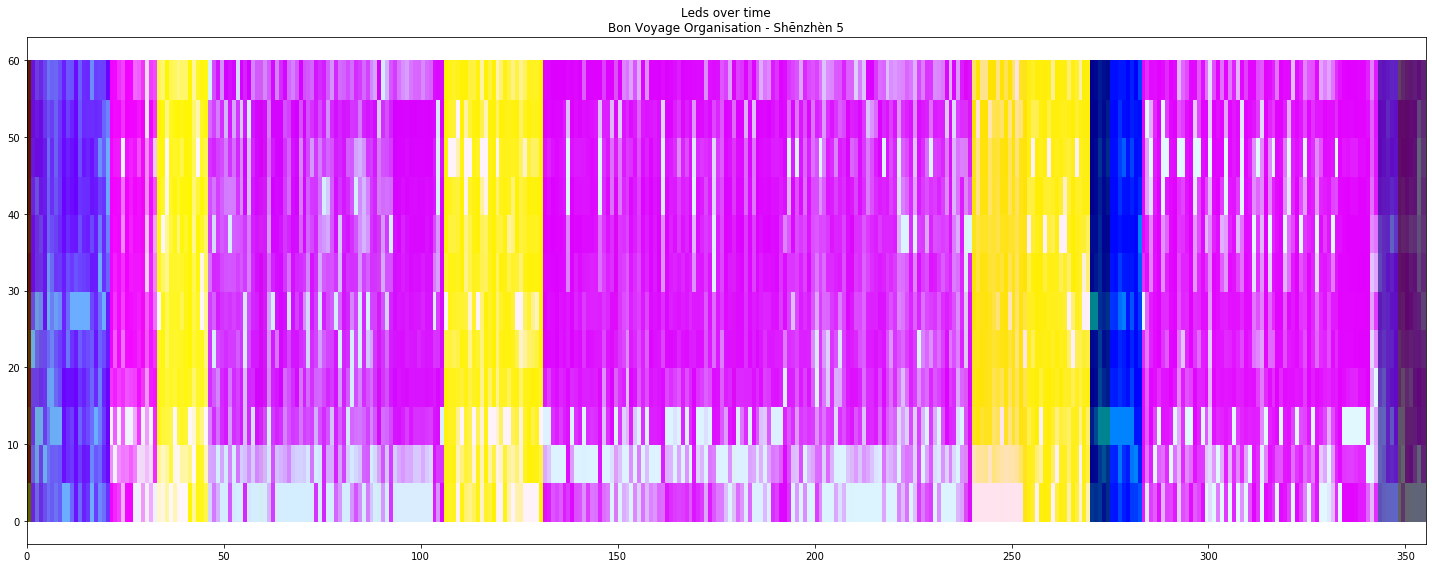
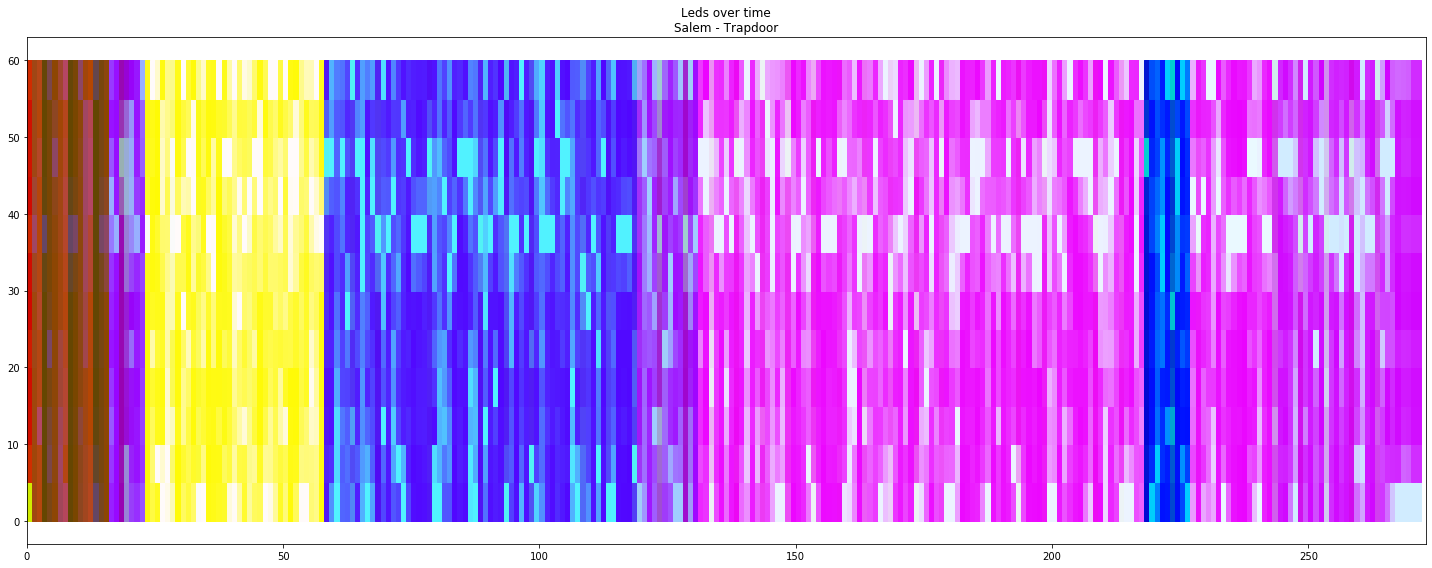



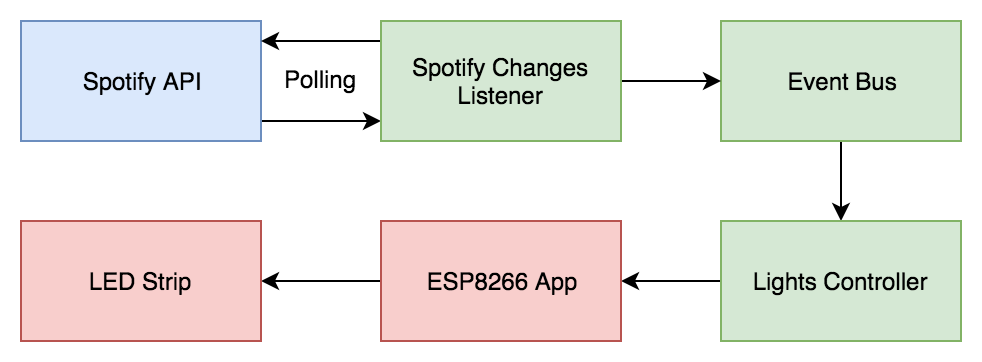

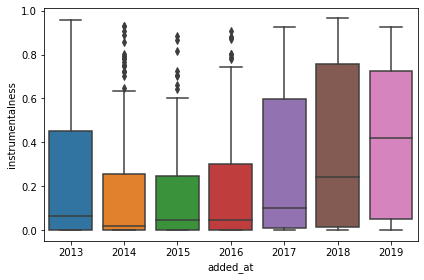
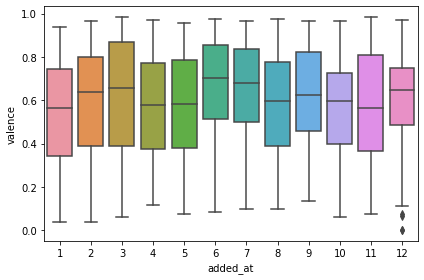
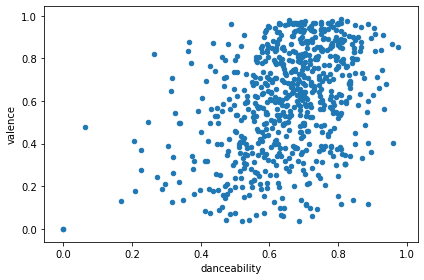
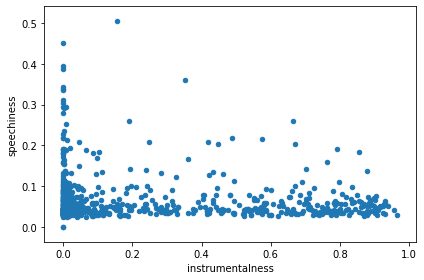
 Not so long ago
I’ve decided to read
Not so long ago
I’ve decided to read  Recently I decided
to read
Recently I decided
to read 
 Not so long ago I wanted to read something
about a large scale architecture and mistakenly decided that
Not so long ago I wanted to read something
about a large scale architecture and mistakenly decided that

{kind=link}