In rerenderer I need an intermediate language that can be interpreted in browser
and on Android. For browser part I chose ClojureScript. Quick note about the language,
it’s an EDSL on Clojure macros, for example:
(let [event (r/new Event "click")
canvas (r/.. document (createElement "canvas"))
width (r/.. window -innerWidth)]
(r/set! (r/.. canvas -width) width)
(r/.. canvas (dispatchEvent event)))
It contains only .., set! and new macros. It’s very similar to Clojure interop with java and ClojureScript
interop with JavaScript. This code is an equivalent of JavaScript code:
var event = new Event("click");
var canvas = document.createElement("canvas");
var width = window.innerWidth;
canvas.width = width;
canvas.dispatchEvent(event):
And macros are just an user friendly facade, inside it produces something like bytecode:
[[:new [:ref "a"] [:static "Event"] [[:val "click"]]]
[:call [:ref "b"] [:static "document"] "createElement" [[:val "canvas"]]]
[:get [:ref "c"] [:static "window"] "innerWidth"]
[:set [:ref "b"] "width" [:ref "c"]]
[:call [:ref "d"] [:ref "b"] "dispatchEvent" [[:ref "a"]]]]
We’ll write interpreter for it. You can notice that bytecode has four instructions:
[:new <result-var> <class-var> [<arguments-vars>]] – creates new object;[:get <result-var> <object-var> <attribute>] – gets attribute of object;[:set <object-var> <attribute> <value-var>] – sets attribute of object;[:call <result-var> <object-var> <method> [<arguments-vars>]] – calls object method.
And also bytecode has one utility instruction:
[:free <object-var>] – removes reference from registry.
Variable can be in three forms:
[:val <value>] – value of primitive type, like double, string or bool, aka pass by value;[:static <value>] – value from global scope, like window or document, similar to pass by reference;[:ref <reference>] – reference to value in registry, aka pass by reference.
So, let’s start with variables and implement function that returns variable value, there we’ll use match macro
from core.match:
(defn extract-var
[registry var]
(match var
[:static x] (aget js/window x) ; variable from global scope, from `window`
[:ref x] (registry x) ; variable from registry
[:val x] x)) ; value
It’s simple, now it’s time to functions that’ll handle instructions. All that functions should have
signature like (registry, *instruction-params) -> registry. We start with function that’ll handle :new:
(defn create-instance
[registry [_ ref-id] cls args]
(let [cls (extract-var registry cls)
js-args (clj->js (into [nil] (map #(extract-var registry %) args)))
constructor (.. js/Function -prototype -bind (apply cls js-args))
inst (new constructor)]
(assoc registry ref-id inst)))
So it’s just creating new instance of cls with args and puts result to registry. You can notice obscure:
js-args (clj->js (into [nil] (map #(extract-var registry %) args)))
constructor (.. js/Function -prototype -bind (apply cls js-args))
inst (new constructor)
We need this because we can’t use apply with new, like (apply new cls args) and also not all
constructors have apply method, so we can’t just call (new (.apply cls js-args)). Interop isn’t nice here
and this code is an equivalent of JavaScript:
new Function.prototype.bind.apply(cls, [null].concat(args))
Next is a function, that’ll handle :set, it’s very simple, we just use aset:
(defn set-attr
[registry obj attr value]
(aset (extract-var registry obj) attr (extract-var registry value))
registry)
And similar for :get with aget:
(defn get-attr
[registry [_ result-ref] ref attr]
(assoc registry result-ref (aget (extract-var registry ref) attr)))
Function for :call is a bit more complicated:
(defn call-method
[registry [_ result-ref] var method args]
(let [obj (extract-var registry var)
js-args (clj->js (mapv #(extract-var registry %) args))
call-result (.apply (aget obj method) obj js-args)]
(assoc registry result-ref call-result)))
We need the obscure part with .apply here, because not all JavaScript functions can be called with
ClojureScript’s apply.
Functions for :free is the easiest:
(defn free
[registry [_ ref]]
(dissoc registry ref))
So now it’s time to write function, that can handle all instructions, it should have signature like
(registry, instruction) -> registry. And it’s very easy to write it with match:
(defn interpret-instruction
[registry instruction]
(try
(match instruction
[:new result-var cls args] (create-instance registry result-var cls args)
[:set var attr value] (set-attr registry var attr value)
[:get result-var var attr] (get-attr registry result-var var attr)
[:call result-var var method args] (call-method registry result-var var
method args)
[:free var] (free registry var))
(catch js/Error e
(.warn js/console "Can't execute instruction" instruction ":" e)
(throw e))))
So now we can interperete instructions one by one, and interpret script with reduce:
(reduce interpret-instruction {} script)
But we forgot about one significant part. How we handle references registry? It’ll be just atom with hash-map:
(def registry-cache (atom {}))
And function, that interpret script and update registry will be just:
(defn interpret!
[script]
(swap! registry-cache #(reduce interpret-instruction % script)))
You can try bytecode interpreter in action:
(new window)
Full code of interpreter.
 Friends recommended me
to read The Clean Coder: A Code of Conduct for Professional Programmers by Robert C. Martin.
And recently I read it. The book explains some parts of engineer’s work, makes some useful points. And proves
them with real life stories. Most of things in the book are well known, but it’s nice
that author describes not only “good path”, but also situations when something gone wrong.
Friends recommended me
to read The Clean Coder: A Code of Conduct for Professional Programmers by Robert C. Martin.
And recently I read it. The book explains some parts of engineer’s work, makes some useful points. And proves
them with real life stories. Most of things in the book are well known, but it’s nice
that author describes not only “good path”, but also situations when something gone wrong.



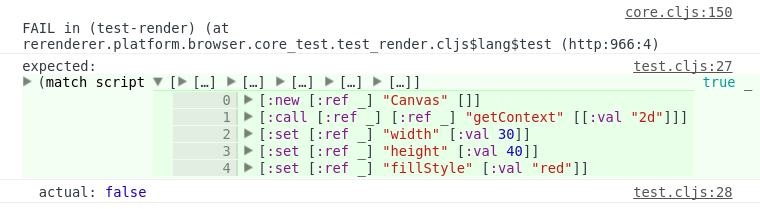
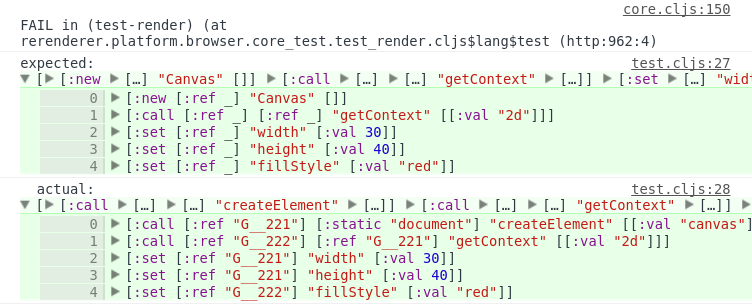
 Lately I’m working a lot with
Lately I’m working a lot with
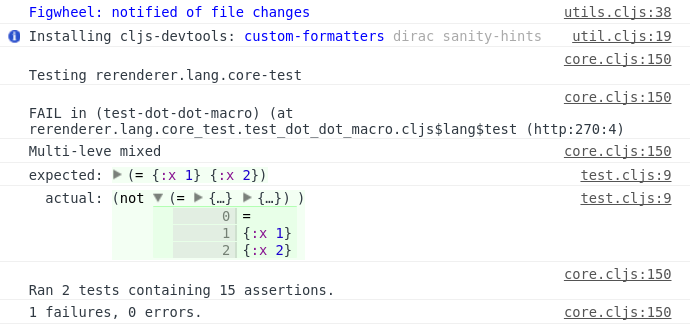
 I’m a bit interested in game development and
I’m a bit interested in game development and  Yesterday I’ve finished reading
Yesterday I’ve finished reading
