
Not so long ago I read that John Carmack uses Lisp for VR, and also I found experiments for Cardboard with three.js and a good article about coding with three.js for Cardboard. I thought it will be good to combine this stuff and try to play with some poor man’s VR with cheap Cardboard and a browser. And use benefits of ClojureScript like figwheel with REPL and livecoding.
So for drawing I decided to use three.js with StereoEffect.js for drawing for both eyes and with DeviceOrientationControls.js for tracking head movements.
First of all we need to prepare a scene, a camera, a renderer for both eyes and a controls for tracking head movements:
(defn get-camera
"Creates camera with desired aspect ratio."
[]
(doto (js/THREE.PerspectiveCamera. 75 (/ (.-innerWidth js/window)
(.-innerHeight js/window))
0.1 1000)
(.. -position (set 0 5 0))))
(defn get-canvas
"Returns canvas that will be fullscreened after a click."
[]
(let [canvas (.getElementById js/document "canvas")]
(.addEventListener canvas "click" #(.webkitRequestFullscreen canvas))
canvas))
(defn get-renderer
"Creates renderer for both eyes."
[]
(let [canvas (get-canvas)
webgl (js/THREE.WebGLRenderer. #js {:canvas canvas})
renderer (js/THREE.StereoEffect. webgl)]
(.setSize renderer (.-innerWidth js/window) (.-innerHeight js/window))
renderer))
(defn set-orientational-contorlls
"Set in atom controlls that tracks device (and head) movements."
[controlls camera e]
(when (and (.-alpha e) (not @controlls))
(let [ctrls (js/THREE.DeviceOrientationControls. camera true)]
(.connect ctrls)
(.update ctrls)
(reset! controlls ctrls))))
(defn get-controlls
"Returns atom with controlls."
[camera]
(let [controlls (atom)]
(.addEventListener js/window "deviceorientation"
#(set-orientational-contorlls controlls camera %))
controlls))
(def scene (js/THREE.Scene.))
(def camera (get-camera))
(def renderer (get-renderer))
(def controlls (get-controlls camera))
And then functions for rendering:
(defn do-render
"Called on each render."
[])
(defn render
"Called on each render. This function not reloads on changes."
[]
(js/requestAnimationFrame render)
(when @controlls
(.update @controlls))
(.updateProjectionMatrix camera)
(do-render)
(.render renderer scene camera))
; Not reload render function when code changed:
(defonce render-started (atom false))
(when-not @render-started
(render)
(reset! render-started true))
When we need to do some actions (change color, rotate, etc) on each render
— we need to change do-render.
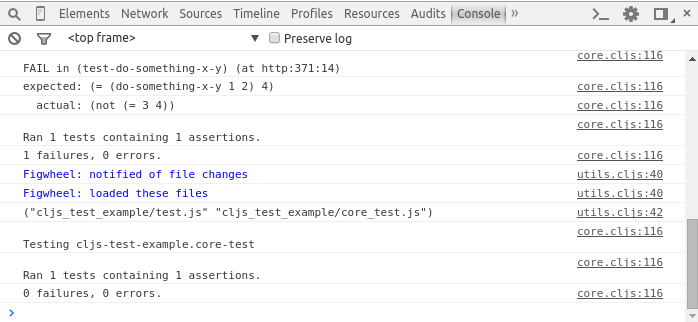
Well, enough with boilerplate, look at some example — two rotating rectangles, you can see this example in the video. The code isn’t good looking, three.js api not so very friendly with ClojureScript, but it readable:
(defn create-rect
"Creates a rect with given color and xyz."
[color x y z]
(js/THREE.Mesh. (js/THREE.BoxGeometry. x y z)
(js/THREE.MeshBasicMaterial. #js {:color color})))
; Creates white rect:
(def rect (create-rect "white" 1 1 1))
(.. rect -position (set 1 1 0))
(.add scene rect)
; Creates yellow rect:
(def other-rect (create-rect "yellow" 1 2 3))
(.. other-rect -position (set -0.5 -2 0))
(.add scene other-rect)
(defn do-render
"Called on each render."
[]
; Rotates white rect:
(set! (.. rect -rotation -x)
(+ (.. rect -rotation -x) 0.01))
(set! (.. rect -rotation -y)
(+ (.. rect -rotation -y) 0.01))
; Rotates yellow rect:
(set! (.. other-rect -rotation -x)
(- (.. other-rect -rotation -x) 0.1))
(set! (.. other-rect -rotation -y)
(+ (.. other-rect -rotation -y) 0.1)))
Let’s see it in action, it’s not so fabulous without Cardboard, but livecoding makes it more interesting:
This way to work with Cardboard has a few problems: we can’t use the magnet trigger and we don’t have special lens distortion correction. And I guess next time I’ll try to use Cardboard SDK for Android with Clojure on Android.
 I was interested how common
data structures were implemented in FP languages and decided to read
I was interested how common
data structures were implemented in FP languages and decided to read
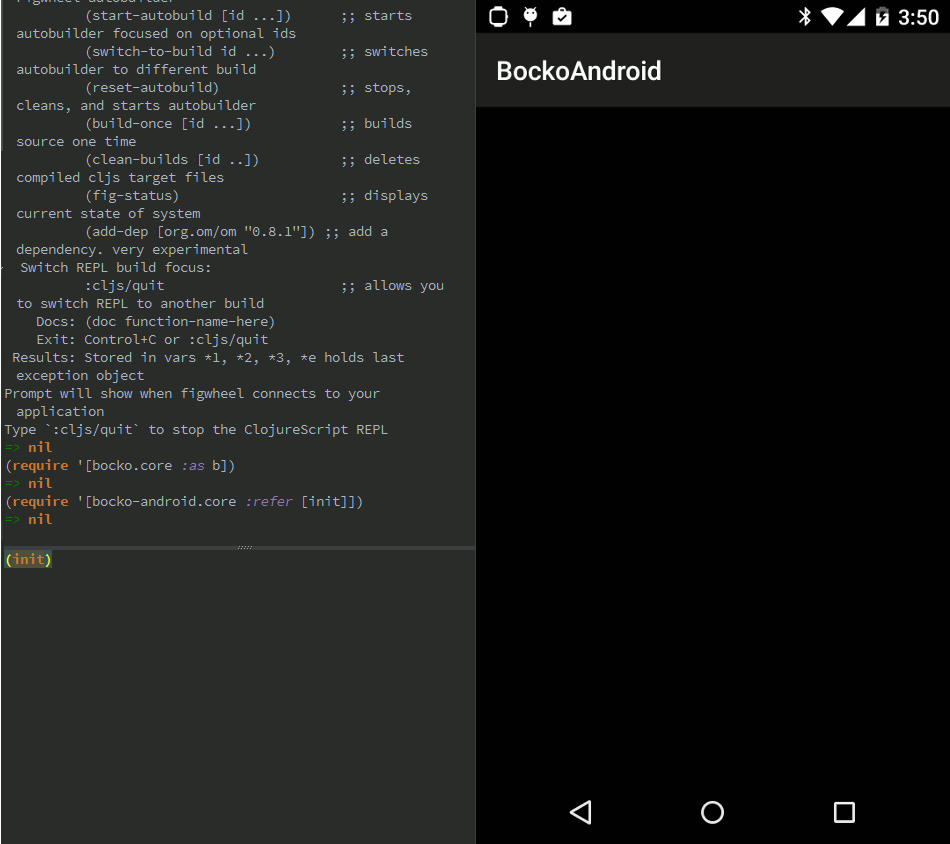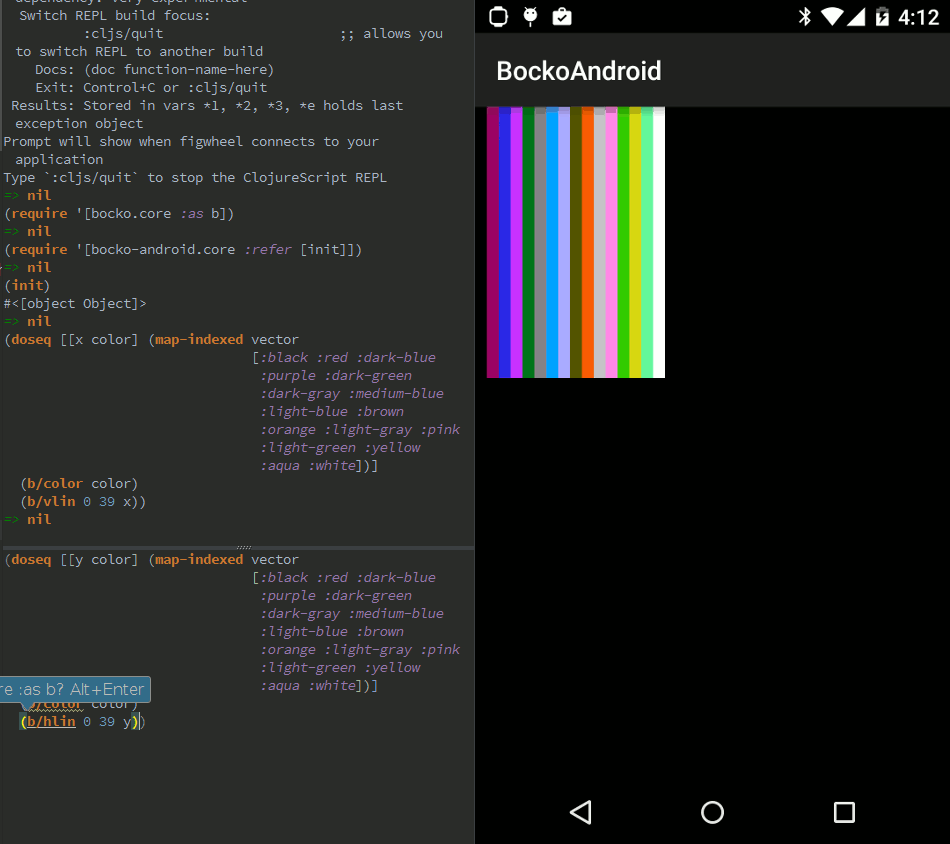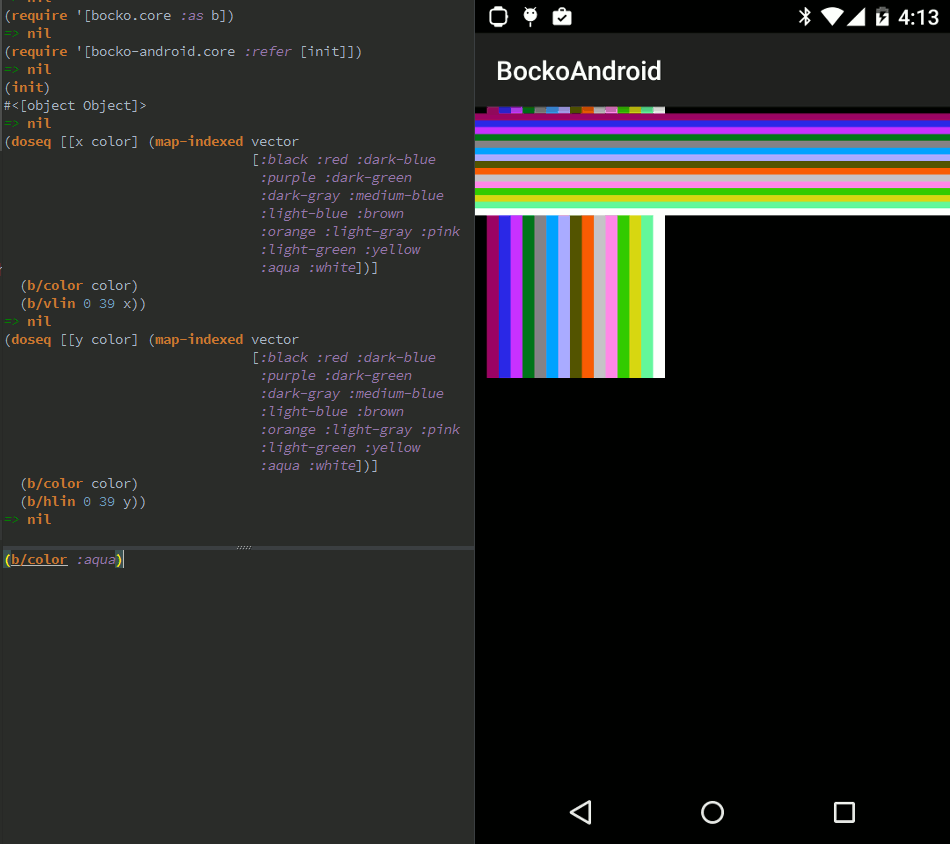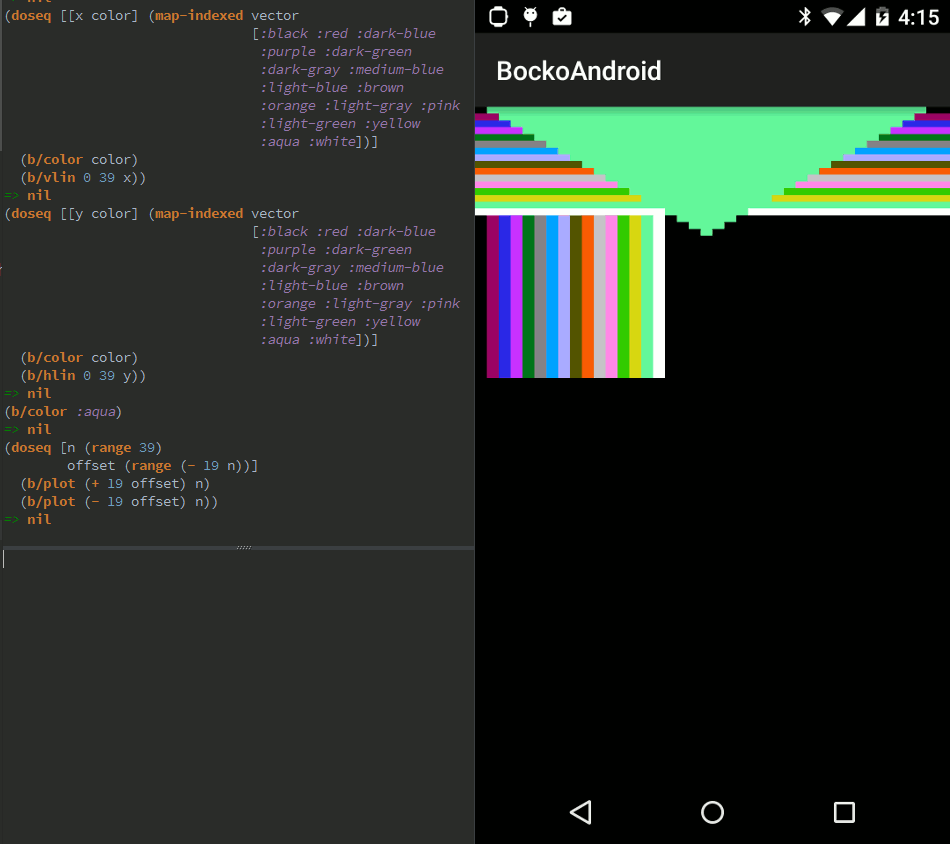
 Few days ago I finished reading
Few days ago I finished reading
