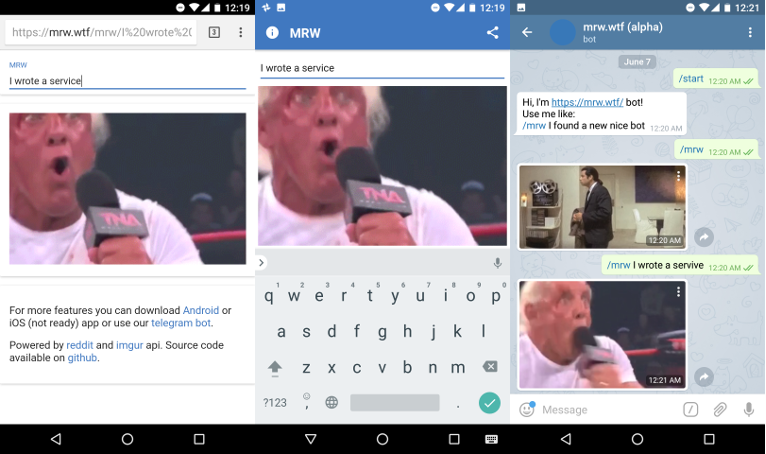
A while ago I discovered that people often use MRW
as a reply in messengers. And not knowing that nowadays even Android keyboard
have an option to search gifs, I decided to write some service with a mobile app,
a web app and even a Telegram bot, that will do that.
The idea was pretty simple, just parse Reddit, somehow index gifs and allow users
to search and share reaction gifs in all possible ways. The result
was mediocre at best.
MRW result is mediocre at best
The first part is the parser,
it’s pretty simple and can do just two things:
- index
n top of all time posts from r/MRW on an initial run;
- index
n top today posts every 12 hours.
While indexing it gets appropriate links from Reddit’s own images hosting or Imgur,
got additional information from nlp-service and put everything in ElasticSearch.
I decided to write it in Clojure because wanted to. The only problem was that Elastisch,
a Clojure client for ElasticSearch, wasn’t (doesn’t?) work with the latest version of ElasticSearch.
But ElasticSearch REST API is neat, and I just used it.
MRW library doesn’t work with the latest elasticsearch

The next and the most RAM consuming part is the nlp-service,
it’s written in Python with NLTK and Flask. It also
can do just two things:
- sentiment analysis of a sentence, like
{"sentiment": "happiness"} for “someone congrats me”;
- VADER, which is a some sort of sentiment analysis too, like
{"pos": 0.9, "neg": 0.1, "neu": 0.2}
for the same sentence.
It doesn’t work very well, because I’m amateur at best in NLP, and had a too small dataset. I was
and still planning to make a better dataset with Mechanical Turk
in the future.
MRW I have too small dataset

The last non-client part is the public facing API,
it’s also very simple, written in Clojure, Ring and Compojure. It has just one endpoint
/api/v1/search/?query=query. It just requests additional information for the query
from nlp-service and searches appropriate gifs in ElasticSearch. Nothing interesting.
MRW public facing api is boring

The first client is the web app (source).
It’s neat, has just one text input for query and written with ClojureScript and
reagent. And it’s so small, that I don’t even
use re-frame here.
MRW the web app is neat

The second client is the mobile app
(source).
It can search for reaction gifs and can share found gifs to other apps. It’s written with
React Native in JavaScript and works only on Android. Yep, I managed to write non-cross-platform
RN app, but at least I’m planning to make it cross-platform and publish it to the AppStore.
MRW I managed to write non-cross-platform RN app

And the last and the most hipsterish client is the Telegram bot
(source). It has three types of responses:
- to
/mrw query with appropriate reaction gif;
- to just
/mrw with famous Travolta gif;
- to
/help with obviously help message.
And it’s written in JavaScript with Node.js Telegram Bot API.
MRW I can’t find Travolta gif

The last part is deploy. Everything is deployed
on docker-cloud. I somehow managed to configure everything a few days
before swarm mode announce,
so it’s just stacks. But it wouldn’t be a problem to migrate to new swarm mode. The service
is deployed as eight containers:
- ElasticSearch;
- nginx proxy;
- letsencrypt nginx proxy companion;
- the nlp-service;
- the public API;
- the parser;
- the web app (data container);
- the Telegram bot.
Almost everything worked out of the box, I only changed nginx proxy image to simplify serving
assets of the web app. And it’s more than nice, when I push changes to github,
docker-cloud rebuilds images and redeploys containers.
MRW almost everything works out of the box

Summing up everything, it was a totally full stack experience from the cluster on docker-cloud
with microservices to the Telegram bot and the mobile app. And the result isn’t
the worst part, the worst part is that as a part of my studying I’ve made
a presentation for future Software Engineers about that service in Czech.
MRW I’ve made a presentation

Sources on github, the web app,
the mobile app,
the Telegram bot.
 Recently I decided to
read something more about Kubernetes and found
The Kubernetes Book by Nigel Poulton.
And I’ve made a wrong choice because it’s an introductory book explaining
basic concepts with very simple examples.
Recently I decided to
read something more about Kubernetes and found
The Kubernetes Book by Nigel Poulton.
And I’ve made a wrong choice because it’s an introductory book explaining
basic concepts with very simple examples. Recently I wanted to read
something about graph databases and in
Recently I wanted to read
something about graph databases and in 

 In
In  Apart from using
Apart from using 

 Recently I wanted to read
something about applications design and distributed systems, so I found
and read
Recently I wanted to read
something about applications design and distributed systems, so I found
and read  Recently I was interested how
networks work and everywhere I found recommendations to read
Recently I was interested how
networks work and everywhere I found recommendations to read
{kind=link}